
The term “abstraction” means showing only important information and hiding details. Data abstraction is the provision of important information about the data to the outside world, hiding details and background implementations.
In C ++, data abstraction is one of the most important and important features of object-oriented programming.
For example:
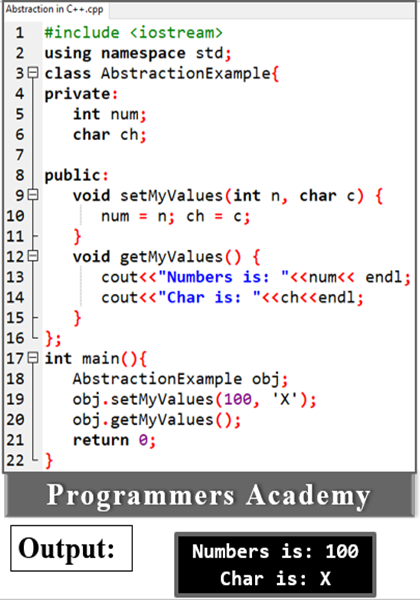
Two Ways of Data Abstraction:
- Abstraction using classes.
- Abstraction in header files.
Abstraction using classes:
You can use classes to implement abstractions in C ++. Classes help you group data members and member functions using the available access specifiers. The class can determine which data members are visible from the outside and which data members are not visible.
For example:
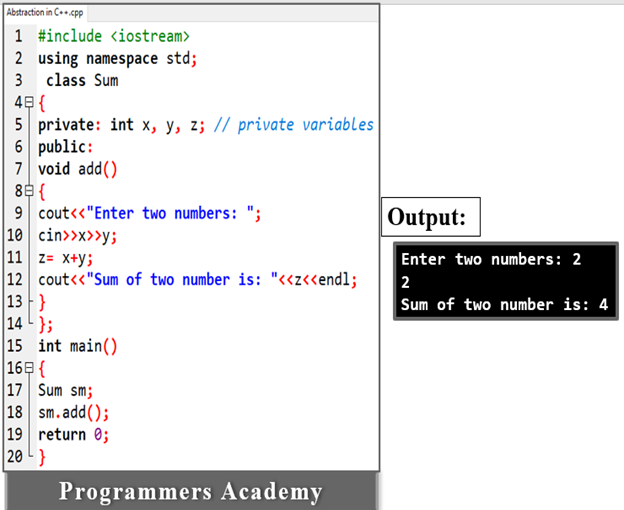
In the previous example, abstraction is achieved through classes. The class “Sum” contains private members x, y, z and can only be accessed from member functions of the class.
Abstraction in Header files:
Another type of abstraction in C ++ is the header file. For example, consider the pow () method in math.h header file. Whenever you need to calculate the power of numbers, you can call the pow () function in the math.h header file and use the arguments without knowing the underlying algorithm that the function is actually calculating the power of the numbers. Pass the number as. ..
For example:
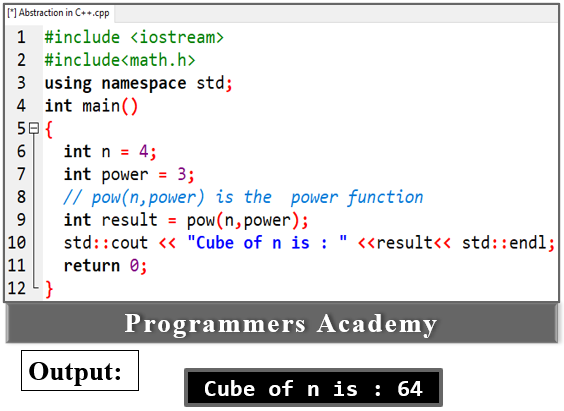
The example above uses the pow () function to calculate 4 raised to the 3rd power. The pow () function is in the math.h header file, which hides all the implementation details of the pow () function.
Abstraction using access specifiers:
Access specifiers are the mainstay for implementing abstractions in C ++. You can use access specifiers to apply restrictions to members of the class. For example:
- Members declared public in the class can be accessed from anywhere in the program.
- Members declared private in a class can only be accessed from within the class. It is not accessible from any part of the code outside of the class.
You can easily implement abstraction by using the above two features provided by the access specifier. For example, a member that defines an internal implementation can be marked as private within a class. And important information that needs to be provided to the outside world can be marked as public. And these public members can access private members while in class.

The above program does not allow direct access to variables a and b, but calls the set () function to set the values of a and b and the display () function to set the values of a and b. will be displayed. B.
Benefits of Data Abstraction:
Data abstraction has two major advantages:
- The interior of the classroom is protected against inadvertent user-level errors that can damage the state of the object.
- Class implementations can evolve over time in response to requirement changes and bug reports without changing user-level code.
By defining data members only in the private section of the class, the author of the class is free to modify the data. If your implementation changes, you just have to look at the class code to see how the changes affect you. If the data is exposed, the function that directly accesses the data member of the above representation may be corrupted.
Advantages of Data Abstraction:
- Data abstraction allows users to write low-level code to avoid errors.
- Data abstraction helps avoid code duplication.
- Helps to reuse code.
- Data abstraction allows you to individually modify the internal implementation of a class without affecting the user.
- You can increase the security of your application or program so that you can only provide important information to your users.
Disadvantages of Data Abstraction:
- Simple speed: To implement the abstraction, the code that you implement must handle cases and situations that are not always necessary or often not necessary in many usage scenarios. This slows down the code compared to the code implemented directly by the operation without using abstractions.
- Code size: This is not a problem for large systems in the world today, but it can occur on small devices and restricted environments. The additional code must be able to fully implement the abstraction, adding the number of lines and ultimately the size of the code. If you don’t implement your code carefully, a lot of extra code will be “extracted” and your executable will be too large, making your device more expensive.
Conclusion of Data Abstraction:
Data abstractions are used to reuse written code and modify internal implementations without affecting the source code. This allows the encoder to protect the data from the outside. Data abstraction plays an important role in avoiding duplicate code that performs the same operation over and over again.
References:
- https://www.geeksforgeeks.org/abstraction-in-c/#:~:text=Data%20abstraction%20refers%20to%20providing,the%20background%20details%20or%20implementation.&text=Abstraction%20using%20Classes%3A%20We%20can,functions%20using%20available%20access%20specifiers.
- https://www.infobrother.com/Tutorial/C++/C++_Data_Abstractionw
