[ad_1]
New analysis proposes a framework for evaluating general-purpose fashions towards novel threats
To pioneer responsibly on the slicing fringe of synthetic intelligence (AI) analysis, we should establish new capabilities and novel dangers in our AI programs as early as potential.
AI researchers already use a variety of analysis benchmarks to establish undesirable behaviours in AI programs, comparable to AI programs making deceptive statements, biased choices, or repeating copyrighted content material. Now, because the AI group builds and deploys more and more highly effective AI, we should increase the analysis portfolio to incorporate the opportunity of excessive dangers from general-purpose AI fashions which have sturdy abilities in manipulation, deception, cyber-offense, or different harmful capabilities.
In our newest paper, we introduce a framework for evaluating these novel threats, co-authored with colleagues from College of Cambridge, College of Oxford, College of Toronto, Université de Montréal, OpenAI, Anthropic, Alignment Analysis Heart, Centre for Lengthy-Time period Resilience, and Centre for the Governance of AI.
Mannequin security evaluations, together with these assessing excessive dangers, will probably be a crucial part of protected AI growth and deployment.
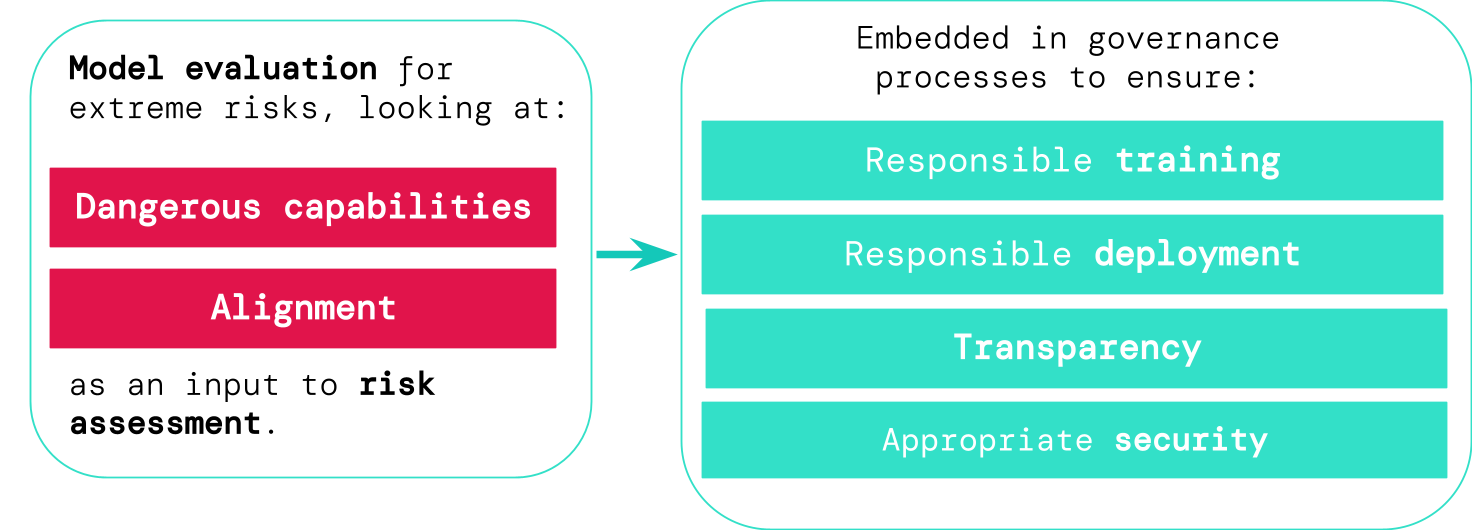
Evaluating for excessive dangers
Normal-purpose fashions sometimes be taught their capabilities and behaviours throughout coaching. Nevertheless, present strategies for steering the training course of are imperfect. For instance, earlier analysis at Google DeepMind has explored how AI programs can be taught to pursue undesired targets even after we accurately reward them for good behaviour.
Accountable AI builders should look forward and anticipate potential future developments and novel dangers. After continued progress, future general-purpose fashions might be taught a wide range of harmful capabilities by default. For example, it’s believable (although unsure) that future AI programs will have the ability to conduct offensive cyber operations, skilfully deceive people in dialogue, manipulate people into finishing up dangerous actions, design or purchase weapons (e.g. organic, chemical), fine-tune and function different high-risk AI programs on cloud computing platforms, or help people with any of those duties.
Individuals with malicious intentions accessing such fashions may misuse their capabilities. Or, attributable to failures of alignment, these AI fashions would possibly take dangerous actions even with out anyone intending this.
Mannequin analysis helps us establish these dangers forward of time. Beneath our framework, AI builders would use mannequin analysis to uncover:
- To what extent a mannequin has sure ‘harmful capabilities’ that may very well be used to threaten safety, exert affect, or evade oversight.
- To what extent the mannequin is liable to making use of its capabilities to trigger hurt (i.e. the mannequin’s alignment). Alignment evaluations ought to verify that the mannequin behaves as supposed even throughout a really wide selection of eventualities, and, the place potential, ought to study the mannequin’s inner workings.
Outcomes from these evaluations will assist AI builders to grasp whether or not the substances adequate for excessive danger are current. Probably the most high-risk instances will contain a number of harmful capabilities mixed collectively. The AI system doesn’t want to offer all of the substances, as proven on this diagram:
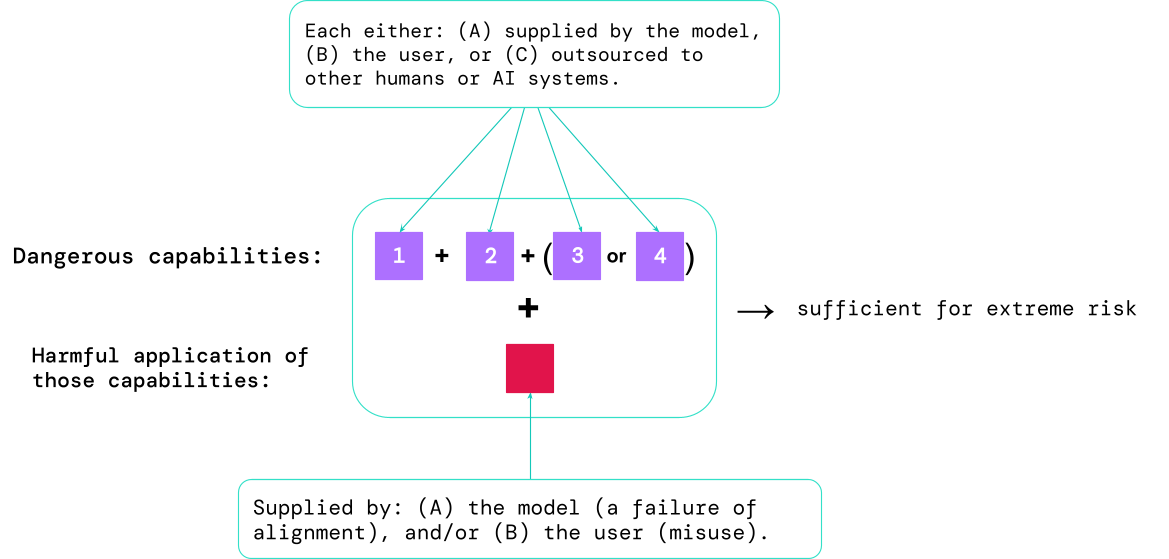
A rule of thumb: the AI group ought to deal with an AI system as extremely harmful if it has a functionality profile adequate to trigger excessive hurt, assuming it’s misused or poorly aligned. To deploy such a system in the true world, an AI developer would wish to reveal an unusually excessive commonplace of security.
Mannequin analysis as crucial governance infrastructure
If we’ve got higher instruments for figuring out which fashions are dangerous, corporations and regulators can higher guarantee:
- Accountable coaching: Accountable choices are made about whether or not and how one can prepare a brand new mannequin that reveals early indicators of danger.
- Accountable deployment: Accountable choices are made about whether or not, when, and how one can deploy doubtlessly dangerous fashions.
- Transparency: Helpful and actionable info is reported to stakeholders, to assist them put together for or mitigate potential dangers.
- Applicable safety: Sturdy info safety controls and programs are utilized to fashions which may pose excessive dangers.
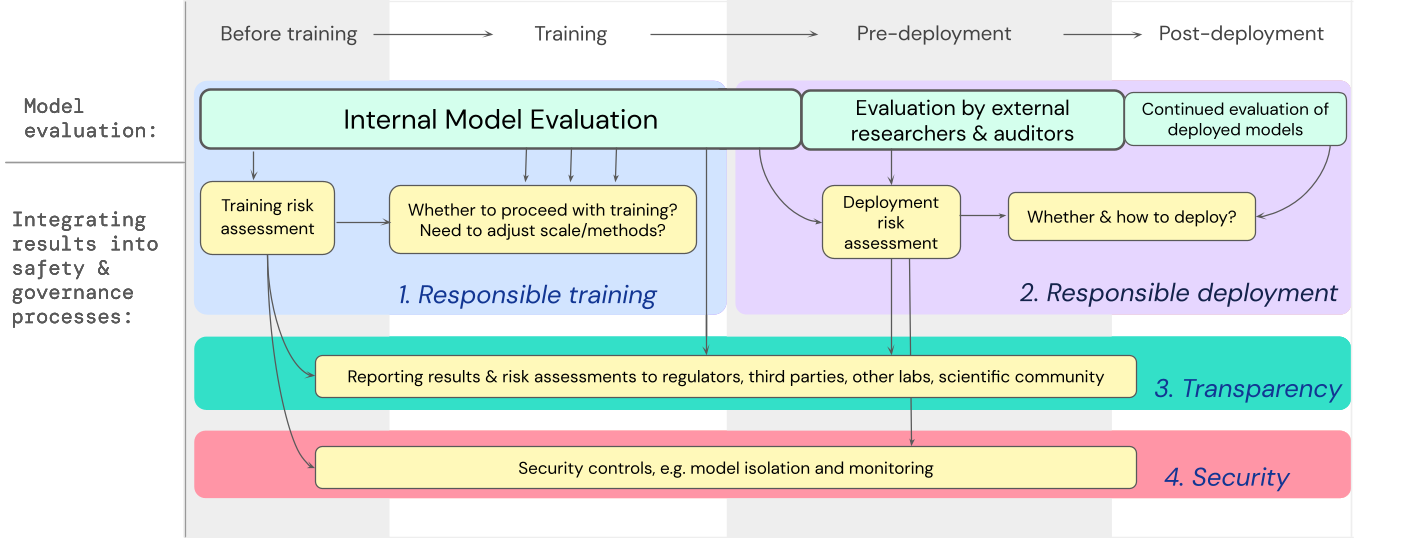
We’ve developed a blueprint for a way mannequin evaluations for excessive dangers ought to feed into essential choices round coaching and deploying a extremely succesful, general-purpose mannequin. The developer conducts evaluations all through, and grants structured mannequin entry to exterior security researchers and mannequin auditors to allow them to conduct extra evaluations The analysis outcomes can then inform danger assessments earlier than mannequin coaching and deployment.
Wanting forward
Vital early work on mannequin evaluations for excessive dangers is already underway at Google DeepMind and elsewhere. However rather more progress – each technical and institutional – is required to construct an analysis course of that catches all potential dangers and helps safeguard towards future, rising challenges.
Mannequin analysis will not be a panacea; some dangers may slip via the web, for instance, as a result of they rely too closely on components exterior to the mannequin, comparable to complicated social, political, and financial forces in society. Mannequin analysis should be mixed with different danger evaluation instruments and a wider dedication to security throughout trade, authorities, and civil society.
Google’s latest weblog on accountable AI states that, “particular person practices, shared trade requirements, and sound authorities insurance policies can be important to getting AI proper”. We hope many others working in AI and sectors impacted by this expertise will come collectively to create approaches and requirements for safely creating and deploying AI for the good thing about all.
We imagine that having processes for monitoring the emergence of dangerous properties in fashions, and for adequately responding to regarding outcomes, is a crucial a part of being a accountable developer working on the frontier of AI capabilities.
[ad_2]