[ad_1]
Markdown has turn into a normal for a lot of trendy content material administration techniques, particularly amongst these focused for developer use. It’s a brief, handy, and easy-to-write content material format for HTML era.
Regardless of the numerous advantages of utilizing Markdown, it additionally comes with challenges. Managing and sustaining tons of or 1000’s of various Markdown and MDX recordsdata is usually a daunting process. Maintaining Markdown’s frontmatter knowledge constant and full isn’t simple, both.
Astro 2.0 goals to sort out these issues by introducing the Content material Collections API, a simple and chic approach to set up content material, hold knowledge integrity, and make Markdown recordsdata type-safe.
On this tutorial, we’ll discover Astro’s Content material Collections API by constructing a easy challenge. Soar forward:
Try the GitHub repository containing the ultimate challenge recordsdata and prepare to observe alongside.
Organising a brand new Astro challenge
Let’s begin by creating a brand new, empty Astro challenge. Run the next in your terminal:
npm create [email protected]
The CLI will information you thru the set up course of. Please just remember to’ve chosen the next choices:
- Set your challenge’s listing as
astro-blog - Set your challenge’s template as
Empty - Set up the challenge’s dependencies
- Use strict TypeScript
- Don’t initialize a brand new Git repository
If you happen to’ve made all of your choices accurately, you need to see one thing just like the under:
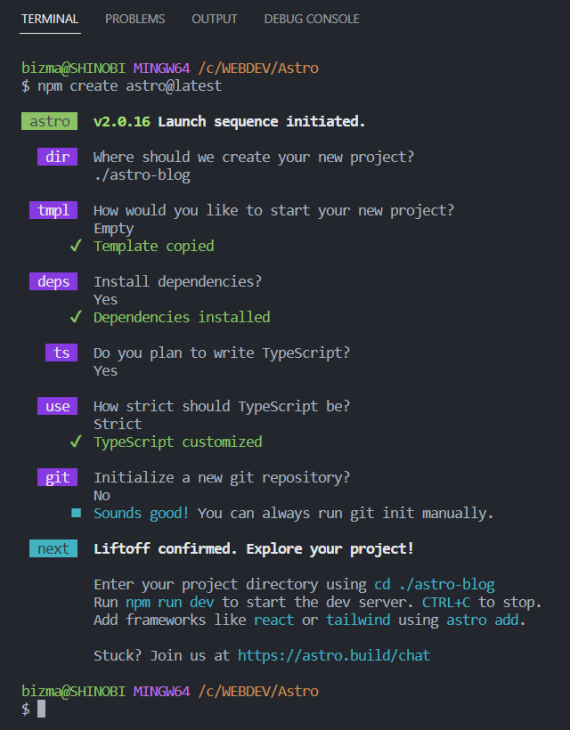
As soon as the challenge’s scaffolding is finished, run the next instructions:
cd astro-blog npm run dev
Then, while you open up localhost:3000 in your browser, you need to see the next:
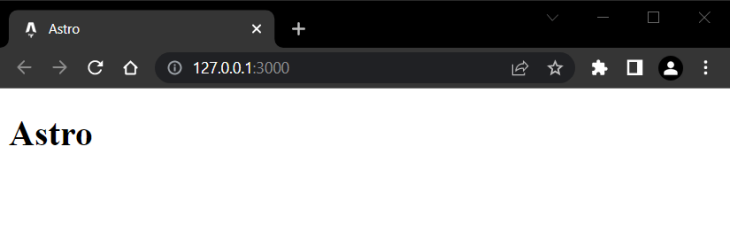
Now, we’re prepared to maneuver on to the enjoyable half.
Constructing a weblog with Astro’s Content material Collections API
On this part, we’ll construct a minimal weblog instance to exhibit the advantages and capabilities of Astro’s Content material Collections API. You could find the recordsdata for the remaining challenge on this GitHub repo.
Our easy weblog will embrace listings for all printed posts and all weblog authors. We may also be capable of view single posts and creator profiles.
Here’s what we have to create:
You need to use the bounce hyperlinks above to navigate to particular steps. In any other case, let’s get began.
Making a schema for our Astro weblog’s content material collections
The very first thing we’re going to create is a schema describing the Markdown frontmatter properties we need to embrace within the content material recordsdata for posts and authors. Having a schema will be sure that the entire frontmatter properties will meet our necessities each time.
Be aware that Astro makes use of Zod, a validation library for TypeScript.
To make use of Astro’s Content material Collections API, we first have to create a src/content material listing. Then, to create a group, we simply create a subdirectory with the identify of the gathering.
Earlier than we start utilizing the Content material Collections API, let’s create a config.ts file contained in the content material folder with the next content material:
import { defineCollection, z } from 'astro:content material';
const weblog = defineCollection({
schema: z.object({
title: z.string(),
description: z.string(),
tags: z.array(z.string()),
creator: z.enum(['David', 'Monica']),
isDraft: z.boolean().default(false),
pubDate: z.string().remodel((str) => new Date(str)),
picture: z.string().non-obligatory(),
}),
});
const authors = defineCollection({
schema: z.object({
identify: z.string(),
e-mail: z.string().e-mail(),
Twitter: z.string().non-obligatory(),
GitHub: z.string().non-obligatory(),
}),
});
export const collections = { weblog, authors };
In case your editor complains about astro:content material — which might happen when the editor doesn’t acknowledge it as a module — restart the server or manually replace the categories by operating the next command:
npx astro sync
This command can also be run routinely together with the astro dev, astro construct, or astro verify instructions. It units up a src/env.d.ts file for sort inferencing and declares the astro:content material module.
The config.ts file isn’t necessary, however to entry the perfect options of the Content material Collections API — like frontmatter schema validation or automated TypeScript typings — you’ll undoubtedly need to embrace it.
Within the code above, we outlined a group by utilizing defineCollection() perform. Then, we used the z utility to create a schema for the frontmatter. In our case, now we have two collections outlined — weblog and authors.
For every publish within the weblog assortment, we need to embrace data such because the title, description, checklist of tags, creator, whether or not the publish is a draft, a publication date, and an non-obligatory picture.
We will outline all these properties by utilizing Zod’s knowledge sorts. For some properties, we additionally use Zod’s schema strategies — for instance:
default()to set the default worth for theisDraftpropertyremodel()to remodel thepubDatestring right into a JavaScriptDateobjectnon-obligatory()to mark thepictureproperty setting as non-obligatory
Be aware that non-obligatory() is critical for the picture property as a result of, in Zod, all the things is required until it’s explicitly marked as non-obligatory.
In an analogous means, for the authors assortment, we outlined identify and e-mail properties for every creator, utilizing the e-mail() validation helper for the e-mail property. We additionally offered non-obligatory properties for the creator’s Twitter and GitHub accounts.
Lastly, we exported the collections for future use by utilizing the export assertion.
Creating content material recordsdata for the weblog and authors collections
Let’s now create the content material recordsdata for our collections. First, create a weblog folder within the src/content material listing. Inside this folder, create a first-post.md file with the next content material:
--- title: "First publish" description: "Lorem ipsum dolor sit amet" tags: ["lorem", "ipsum"] pubDate: "2022-07-08" creator: "David" --- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Vitae ultricies leo integer malesuada nunc vel risus commodo viverra. Adipiscing enim eu turpis egestas pretium. Euismod elementum nisi quis eleifend quam adipiscing. In hac habitasse platea dictumst vestibulum. Sagittis purus sit amet volutpat. Netus et malesuada fames ac turpis egestas. Eget magna fermentum iaculis eu non diam phasellus vestibulum lorem. Varius sit amet mattis vulputate enim. Habitasse platea dictumst quisque sagittis. Integer quis auctor elit sed vulputate mi. Dictumst quisque sagittis purus sit amet.
Moreover, create a second-post.md file with the next content material:
--- title: "Second publish" description: "Lorem ipsum dolor sit amet" tags: ["lorem", "ipsum"] pubDate: "2022-07-18" creator: "Monica" --- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Vitae ultricies leo integer malesuada nunc vel risus commodo viverra. Adipiscing enim eu turpis egestas pretium. Euismod elementum nisi quis eleifend quam adipiscing. In hac habitasse platea dictumst vestibulum. Sagittis purus sit amet volutpat. Netus et malesuada fames ac turpis egestas. Eget magna fermentum iaculis eu non diam phasellus vestibulum lorem. Varius sit amet mattis vulputate enim. Habitasse platea dictumst quisque sagittis. Integer quis auctor elit sed vulputate mi. Dictumst quisque sagittis purus sit amet.
Now, create an authors folder within the src/content material listing. Within the authors folder, create a pattern creator file referred to as david.md with the next content material:
--- identify: "David Davidson" e-mail: "[email protected]" --- David's bio.
We’ll additionally create a second creator file referred to as monica.md with the next content material:
--- identify: "Monica Davidson" e-mail: "[email protected]" --- Monica's bio.
Making a base structure for the weblog’s pages
Now we have to create a base structure shared throughout all weblog pages. Create a layouts folder within the src listing. Add a BaseLayout.astro file inside with the next content material:
<html lang="en">
<head>
<meta charset="utf-8" />
<hyperlink rel="icon" sort="picture/svg+xml" href="http://weblog.logrocket.com/favicon.svg" />
<meta identify="viewport" content material="width=device-width" />
<meta identify="generator" content material={Astro.generator} />
<title>Astro Weblog</title>
</head>
<physique>
<header>
<nav>
<a href="http://weblog.logrocket.com/">Weblog</a> -
<a href="http://weblog.logrocket.com/authors">Authors</a>
</nav>
</header>
<fundamental>
<slot />
</fundamental>
</physique>
</html>
This markup units the bottom HTML construction of our weblog. We added hyperlinks for the weblog publish and creator listings. We additionally used the <slot /> element to outline the place the content material of the pages shall be injected.
Creating a listing of posts
After all of the preparation work we’ve completed to date, it’s time to create a listing of weblog posts. To take action, open the index.astro file contained in the src/pages listing and exchange its content material with the next:
---
import { getCollection } from 'astro:content material';
import BaseLayout from '../layouts/BaseLayout.astro';
const posts = (await getCollection('weblog', ({ knowledge }) => {
return knowledge.isDraft !== true;
})).type(
(a, b) => b.knowledge.pubDate.valueOf() - a.knowledge.pubDate.valueOf()
);
---
<BaseLayout>
<part>
<ul>
{
posts.map((publish) => (
<li>
<a href={`/weblog/${publish.slug}/`}>{publish.knowledge.title}</a>
<p>by <a href={`/authors/${publish.knowledge.creator.toLowerCase()}/`}>{publish.knowledge.creator}</a>,
printed {publish.knowledge.pubDate.toDateString()},
tags: <sturdy>{publish.knowledge.tags.be part of(", ")}</sturdy>
</p>
<p>{publish.knowledge.description}</p>
</li>
))
}
</ul>
</part>
</BaseLayout>
Right here, we first used the getCollection() perform to retrieve the weblog assortment.
We additionally used the “filter” callback perform to filter the gathering to incorporate solely posts that are printed. The knowledge property within the callback represents all properties within the frontmatter.
Extra nice articles from LogRocket:
Then, we sorted the posts in reverse order so the final publish reveals first.
Subsequent, we used the bottom structure element we created earlier to wrap the checklist of the posts. After, we created the checklist by iterating over the posts.
For every publish, we‘re together with a title, a byline containing the creator identify, publication date, and tags, and an outline that we get from the publish.knowledge prop. To create a hyperlink for every publish, we’re utilizing the publish.slug prop.
Now, when you open your browser you need to see a listing of the posts as anticipated:
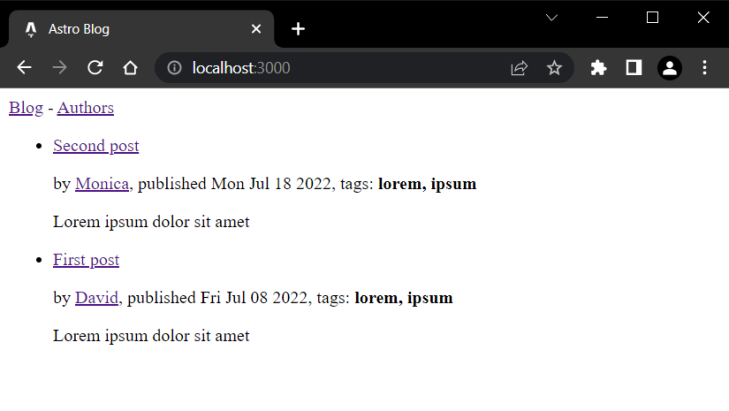
Nice! Nevertheless, when you click on on particular person publish hyperlinks, you’ll get a 404 error web page. It is because to preview particular person posts, we have to create dynamic routes for every considered one of them.
Creating dynamic routes for single posts
For recordsdata inside src/pages, routes are created routinely by default, however for assortment recordsdata inside src/content material, we have to create the routes manually.
To take action, create a weblog folder contained in the src/pages listing and put a […slug].astro file in it with the next content material:
---
import { CollectionEntry, getCollection } from 'astro:content material';
import BaseLayout from '../../layouts/BaseLayout.astro';
export async perform getStaticPaths() {
const posts = await getCollection('weblog');
return posts.map((publish) => ({
params: { slug: publish.slug },
props: publish,
}));
}
sort Props = CollectionEntry<'weblog'>;
const publish = Astro.props;
const { Content material } = await publish.render();
---
<BaseLayout>
<article>
<h1 class="title">{publish.knowledge.title}</h1>
<p>by <a href={`/authors/${publish.knowledge.creator.toLowerCase()}/`}>{publish.knowledge.creator}</a>,
printed {publish.knowledge.pubDate.toDateString()},
tags: <sturdy>{publish.knowledge.tags.be part of(", ")}</sturdy>
</p>
<hr />
<Content material />
</article>
</BaseLayout>
To create a number of pages from a single element inside src/pages, we use the getStaticPaths() perform. In our case above, we queried the content material of the weblog assortment after which iterated over its entries to create URL paths by utilizing the slug property.
Subsequent, we acquired the gathering’s entry from the Astro props. Then, we rendered the entry’s content material by utilizing the render() perform. Within the HTML template, we used the publish prop to show the mandatory publish’s particulars, together with the <Content material /> element to render the publish’s content material.
Now, when you click on on a person publish hyperlink, you need to see it displayed accurately as within the screenshot under:
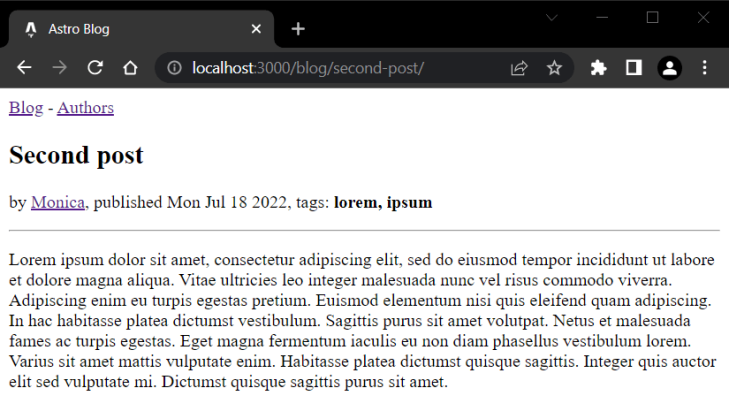
Creating a listing of authors
Now it’s time to do the identical job for the authors assortment.
Let’s begin by creating an authors folder contained in the src/pages listing and including an index.astro file in it with the next content material:
---
import { getCollection } from 'astro:content material';
import BaseLayout from '../../layouts/BaseLayout.astro';
const authors = await getCollection('authors');
---
<BaseLayout>
<part>
<ul>
{
authors.map((creator) => (
<li>
<a href={`/authors/${creator.slug}/`}>{creator.knowledge.identify}</a>
<p>{creator.knowledge.e-mail}</p>
</li>
))
}
</ul>
</part>
</BaseLayout>
Right here, we’re querying the authors assortment, then iterating over its entries to create the checklist of the authors.
Right here is how the checklist ought to look:
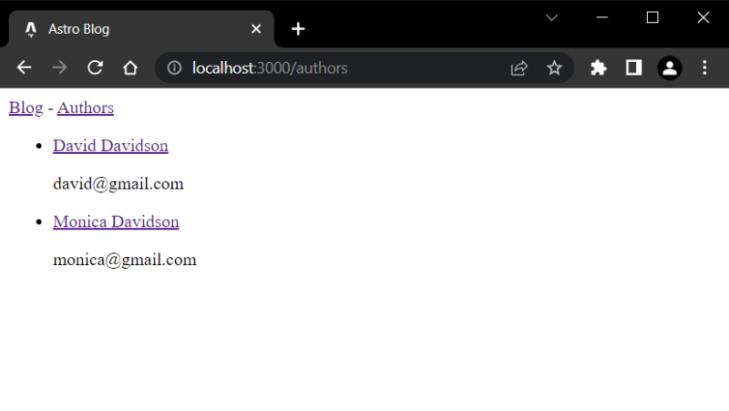
Subsequent, we’ll repeat the identical steps from the weblog assortment to create dynamic routes for the authors assortment entries.
Creating dynamic routes for particular person creator profiles
Within the src/pages/authors listing, add a [...slug].astro file with the next content material:
---
import { CollectionEntry, getCollection } from 'astro:content material';
import BaseLayout from '../../layouts/BaseLayout.astro';
export async perform getStaticPaths() {
const authors = await getCollection('authors');
return authors.map((creator) => ({
params: { slug: creator.slug },
props: creator,
}));
}
sort Props = CollectionEntry<'authors'>;
const creator = Astro.props;
const { Content material } = await creator.render();
---
<BaseLayout>
<article>
<h1 class="title">{creator.knowledge.identify}</h1>
<hr />
<Content material />
</article>
</BaseLayout>
Right here is how an creator profile ought to now look:
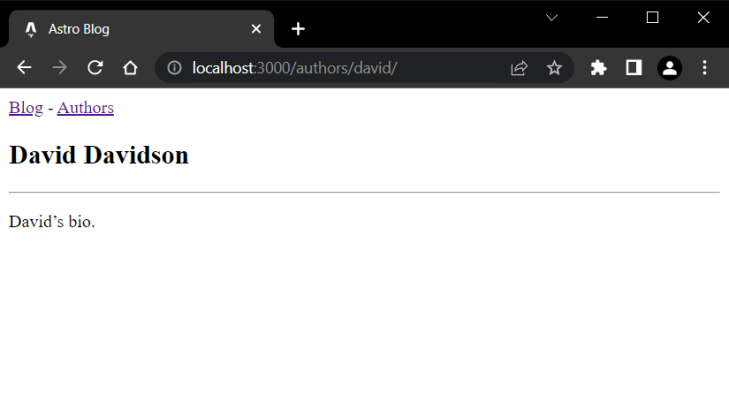
For the sake of simplicity, I’ve not used any CSS styling within the above examples. However in a real-world app, you’ll undoubtedly want some sort of styling. For extra details about how one can implement CSS in your app, verify the official Astro CSS styling information.
Utilizing the Content material Collections API for higher error dealing with
One of many largest benefits of Astro’s Content material Collections API is how errors are dealt with.
To exhibit this, open second-post.md and delete the creator property. If you accomplish that, you’ll get the next error:
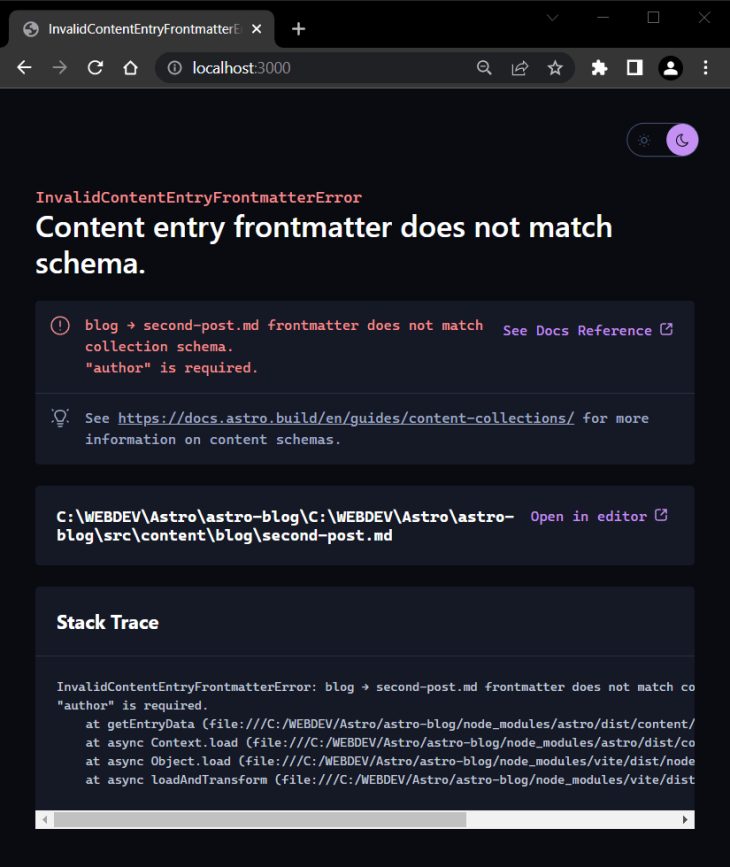
As you’ll be able to see, the error is fairly descriptive and particular, displayed in a wonderful error overlay with the next helpful particulars:
- Error description with the precise filename the place the error occurred
- A path to the file together with a hyperlink to open that file immediately in your code editor
- Hints for the place to look within the docs that can assist you debug your problem
With this data, you need to be capable of rapidly perceive and resolve the error.
Conclusion
On this article, we explored the Astro Content material Collections API by constructing a easy, minimal weblog. We noticed how simple the Content material Collections API is to make use of — and the way highly effective it truly is.
To summarize its fundamental advantages and benefits, Astro’s Content material Collections API gives:
- Sort security in your frontmatter
- Autocomplete for frontmatter properties
- Higher error dealing with
- Constant frontmatter construction
For extra data and sensible makes use of, go to the official Astro Content material Collections information. You probably have any questions, be happy to remark under!
Are you including new JS libraries to enhance efficiency or construct new options? What in the event that they’re doing the other?
There’s little doubt that frontends are getting extra complicated. As you add new JavaScript libraries and different dependencies to your app, you’ll want extra visibility to make sure your customers don’t run into unknown points.
LogRocket is a frontend software monitoring answer that allows you to replay JavaScript errors as in the event that they occurred in your personal browser so you’ll be able to react to bugs extra successfully.

LogRocket works completely with any app, no matter framework, and has plugins to log further context from Redux, Vuex, and @ngrx/retailer. As an alternative of guessing why issues occur, you’ll be able to mixture and report on what state your software was in when a difficulty occurred. LogRocket additionally screens your app’s efficiency, reporting metrics like shopper CPU load, shopper reminiscence utilization, and extra.
Construct confidently — Begin monitoring free of charge.
[ad_2]