
[ad_1]
Giant Language Fashions (LLMs) like PaLM or GPT-3 confirmed that scaling transformers to lots of of billions of parameters improves efficiency and unlocks emergent talents. The most important dense fashions for picture understanding, nonetheless, have reached solely 4 billion parameters, regardless of analysis indicating that promising multimodal fashions like PaLI proceed to learn from scaling imaginative and prescient fashions alongside their language counterparts. Motivated by this, and the outcomes from scaling LLMs, we determined to undertake the following step within the journey of scaling the Imaginative and prescient Transformer.
In “Scaling Imaginative and prescient Transformers to 22 Billion Parameters”, we introduce the largest dense imaginative and prescient mannequin, ViT-22B. It’s 5.5x bigger than the earlier largest imaginative and prescient spine, ViT-e, which has 4 billion parameters. To allow this scaling, ViT-22B incorporates concepts from scaling textual content fashions like PaLM, with enhancements to each coaching stability (utilizing QK normalization) and coaching effectivity (with a novel strategy referred to as asynchronous parallel linear operations). On account of its modified structure, environment friendly sharding recipe, and bespoke implementation, it was in a position to be skilled on Cloud TPUs with a excessive {hardware} utilization1. ViT-22B advances the cutting-edge on many imaginative and prescient duties utilizing frozen representations, or with full fine-tuning. Additional, the mannequin has additionally been efficiently utilized in PaLM-e, which confirmed that a big mannequin combining ViT-22B with a language mannequin can considerably advance the cutting-edge in robotics duties.
Structure
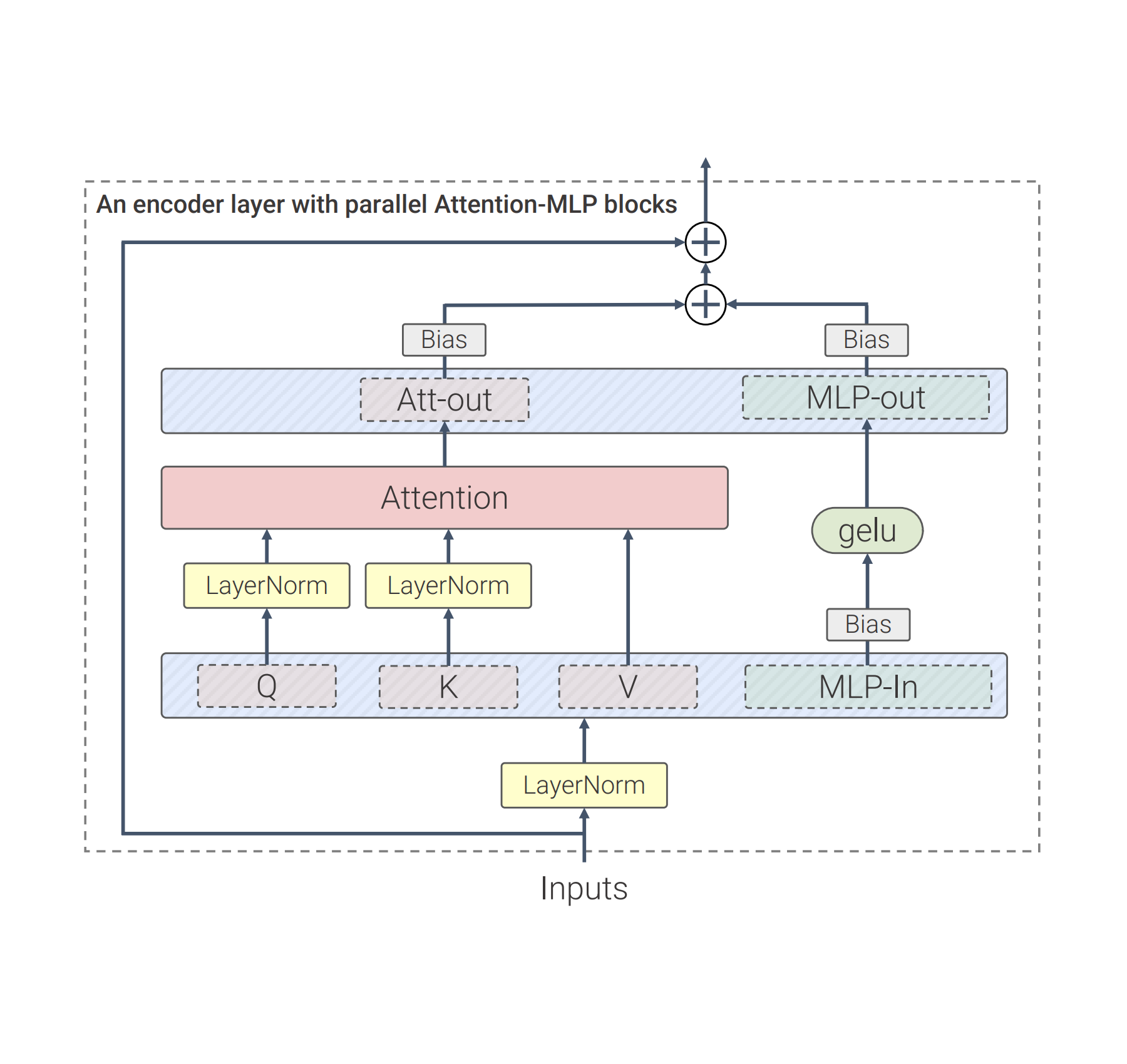
Our work builds on many advances from LLMs, corresponding to PaLM and GPT-3. In comparison with the usual Imaginative and prescient Transformer structure, we use parallel layers, an strategy during which consideration and MLP blocks are executed in parallel, as an alternative of sequentially as in the usual Transformer. This strategy was utilized in PaLM and diminished coaching time by 15%.
Secondly, ViT-22B omits biases within the QKV projections, a part of the self-attention mechanism, and within the LayerNorms, which will increase utilization by 3%. The diagram under exhibits the modified transformer structure utilized in ViT-22B:
 |
| ViT-22B transformer encoder structure makes use of parallel feed-forward layers, omits biases in QKV and LayerNorm layers and normalizes Question and Key projections. |
Fashions at this scale necessitate “sharding” — distributing the mannequin parameters in numerous compute gadgets. Alongside this, we additionally shard the activations (the intermediate representations of an enter). Even one thing so simple as a matrix multiplication necessitates additional care, as each the enter and the matrix itself are distributed throughout gadgets. We develop an strategy referred to as asynchronous parallel linear operations, whereby communications of activations and weights between gadgets happen concurrently computations within the matrix multiply unit (the a part of the TPU holding the overwhelming majority of the computational capability). This asynchronous strategy minimizes the time ready on incoming communication, thus growing system effectivity. The animation under exhibits an instance computation and communication sample for a matrix multiplication.
 |
| Asynchronized parallel linear operation. The aim is to compute the matrix multiplication y = Ax, however each the matrix A and activation x are distributed throughout totally different gadgets. Right here we illustrate how it may be carried out with overlapping communication and computation throughout gadgets. The matrix A is column-sharded throughout the gadgets, every holding a contiguous slice, every block represented as Aij. Extra particulars are within the paper. |
At first, the brand new mannequin scale resulted in extreme coaching instabilities. The normalization strategy of Gilmer et al. (2023, upcoming) resolved these points, enabling easy and secure mannequin coaching; that is illustrated under with instance coaching progressions.
 |
| The impact of normalizing the queries and keys (QK normalization) within the self-attention layer on the coaching dynamics. With out QK normalization (purple) gradients change into unstable and the coaching loss diverges. |
Outcomes
Right here we spotlight some outcomes of ViT-22B. Be aware that within the paper we additionally discover a number of different downside domains, like video classification, depth estimation, and semantic segmentation.
For instance the richness of the realized illustration, we practice a textual content mannequin to provide representations that align textual content and picture representations (utilizing LiT-tuning). Under we present a number of outcomes for out-of-distribution pictures generated by Parti and Imagen:
 |
| Examples of picture+textual content understanding for ViT-22B paired with a textual content mannequin. The graph exhibits normalized likelihood distribution for every description of a picture. |
Human object recognition alignment
To learn the way aligned ViT-22B classification selections are with human classification selections, we evaluated ViT-22B fine-tuned with totally different resolutions on out-of-distribution (OOD) datasets for which human comparability information is accessible by way of the model-vs-human toolbox. This toolbox measures three key metrics: How effectively do fashions deal with distortions (accuracy)? How totally different are human and mannequin accuracies (accuracy distinction)? Lastly, how related are human and mannequin error patterns (error consistency)? Whereas not all fine-tuning resolutions carry out equally effectively, ViT-22B variants are cutting-edge for all three metrics. Moreover, the ViT-22B fashions even have the very best ever recorded form bias in imaginative and prescient fashions. Which means that they largely use object form, reasonably than object texture, to tell classification selections — a technique identified from human notion (which has a form bias of 96%). Customary fashions (e.g., ResNet-50, which has aa ~20–30% form bias) usually classify pictures just like the cat with elephant texture under in accordance with the feel (elephant); fashions with a excessive form bias are inclined to concentrate on the form as an alternative (cat). Whereas there are nonetheless many necessary variations between human and mannequin notion, ViT-22B exhibits elevated similarities to human visible object recognition.
 |
| Cat or elephant? Automobile or clock? Fowl or bicycle? Instance pictures with the form of 1 object and the feel of a unique object, used to measure form/texture bias. |
 |
| Form bias analysis (increased = extra shape-biased). Many imaginative and prescient fashions have a low form / excessive texture bias, whereas ViT-22B fine-tuned on ImageNet (purple, inexperienced, blue skilled on 4B pictures as indicated by brackets after mannequin names, except skilled on ImageNet solely) have the very best form bias recorded in a ML mannequin thus far, bringing them nearer to a human-like form bias. |
Out-of-distribution efficiency
Measuring efficiency on OOD datasets helps assess generalization. On this experiment we assemble label-maps (mappings of labels between datasets) from JFT to ImageNet and in addition from ImageNet to totally different out-of-distribution datasets like ObjectNet (outcomes after pre-training on this information proven within the left curve under). Then the fashions are absolutely fine-tuned on ImageNet.
We observe that scaling Imaginative and prescient Transformers will increase OOD efficiency: despite the fact that ImageNet accuracy saturates, we see a big improve on ObjectNet from ViT-e to ViT-22B (proven by the three orange dots within the higher proper under).
 |
| Although ImageNet accuracy saturates, we see a big improve in efficiency on ObjectNet from ViT-e/14 to ViT-22B. |
Linear probe
Linear probe is a way the place a single linear layer is skilled on high of a frozen mannequin. In comparison with full fine-tuning, that is less expensive to coach and simpler to arrange. We noticed that the linear probe of ViT-22B efficiency approaches that of state-of-the-art full fine-tuning of smaller fashions utilizing high-resolution pictures (coaching with increased decision is mostly rather more costly, however for a lot of duties it yields higher outcomes). Listed here are outcomes of a linear probe skilled on the ImageNet dataset and evaluated on the ImageNet validation dataset and different OOD ImageNet datasets.
Distillation
The information of the larger mannequin will be transferred to a smaller mannequin utilizing the distillation technique. That is useful as massive fashions are slower and costlier to make use of. We discovered that ViT-22B information will be transferred to smaller fashions like ViT-B/16 and ViT-L/16, attaining a brand new cutting-edge on ImageNet for these mannequin sizes.
Equity and bias
ML fashions will be vulnerable to unintended unfair biases, corresponding to choosing up spurious correlations (measured utilizing demographic parity) or having efficiency gaps throughout subgroups. We present that scaling up the scale helps in mitigating such points.
First, scale affords a extra favorable tradeoff frontier — efficiency improves with scale even when the mannequin is post-processed after coaching to regulate its stage of demographic parity under a prescribed, tolerable stage. Importantly, this holds not solely when efficiency is measured when it comes to accuracy, but additionally different metrics, corresponding to calibration, which is a statistical measure of the truthfulness of the mannequin’s estimated chances. Second, classification of all subgroups tends to enhance with scale as demonstrated under. Third, ViT-22B reduces the efficiency hole throughout subgroups.
 |
 |
| High: Accuracy for every subgroup in CelebA earlier than debiasing. Backside: The y-axis exhibits absolutely the distinction in efficiency throughout the 2 particular subgroups highlighted on this instance: females and males. ViT-22B has a small hole in efficiency in comparison with smaller ViT architectures. |
Conclusions
We’ve introduced ViT-22B, at the moment the most important imaginative and prescient transformer mannequin at 22 billion parameters. With small however important modifications to the unique structure, we achieved wonderful {hardware} utilization and coaching stability, yielding a mannequin that advances the cutting-edge on a number of benchmarks. Nice efficiency will be achieved utilizing the frozen mannequin to provide embeddings after which coaching skinny layers on high. Our evaluations additional present that ViT-22B exhibits elevated similarities to human visible notion on the subject of form and texture bias, and affords advantages in equity and robustness, when in comparison with current fashions.
Acknowledgements
It is a joint work of Mostafa Dehghani, Josip Djolonga, Basil Mustafa, Piotr Padlewski, Jonathan Heek, Justin Gilmer, Andreas Steiner, Mathilde Caron, Robert Geirhos, Ibrahim Alabdulmohsin, Rodolphe Jenatton, Lucas Beyer, Michael Tschannen, Anurag Arnab, Xiao Wang, Carlos Riquelme, Matthias Minderer, Joan Puigcerver, Utku Evci, Manoj Kumar, Sjoerd van Steenkiste, Gamaleldin Fathy, Elsayed Aravindh Mahendran, Fisher Yu, Avital Oliver, Fantine Huot, Jasmijn Bastings, Mark Patrick Collier, Alexey Gritsenko, Vighnesh Birodkar, Cristina Vasconcelos, Yi Tay, Thomas Mensink, Alexander Kolesnikov, Filip Pavetić, Dustin Tran, Thomas Kipf, Mario Lučić, Xiaohua Zhai, Daniel Keysers Jeremiah Harmsen, and Neil Houlsby
We want to thank Jasper Uijlings, Jeremy Cohen, Arushi Goel, Radu Soricut, Xingyi Zhou, Lluis Castrejon, Adam Paszke, Joelle Barral, Federico Lebron, Blake Hechtman, and Peter Hawkins. Their experience and unwavering assist performed a vital function within the completion of this paper. We additionally acknowledge the collaboration and dedication of the gifted researchers and engineers at Google Analysis.
1Be aware: ViT-22B has 54.9% mannequin FLOPs utilization (MFU) whereas PaLM reported
46.2% MFU and we measured 44.0% MFU for ViT-e on the identical {hardware}. ↩
[ad_2]
